Catalog Search Architecture
Overview
As of April 2019 the Catalog Search functionality was upgraded to Elasticsearch. This upgrade provides a number of benefits, chief among them are improved relevance and accuracy, and dramatically improved performance -- response time is much more consistent and generally twice as fast. This new functionality will affect the CMS API, Playback API, Studio interactive search and the catalog search methods.
While Brightcove has invested a substantial amount of effort in making Elasticsearch results consistent there are differences, and there is some small possibility that if you have coded specific dependencies on search results your integration may not behave as expected.
Search Result Differences and Impact
In studying the potential impact, Brightcove has found that more than 90% of searches return results that match in terms of the number of results returned. This is an indicator that expected results should not be different enough to cause any problems with API integrations.
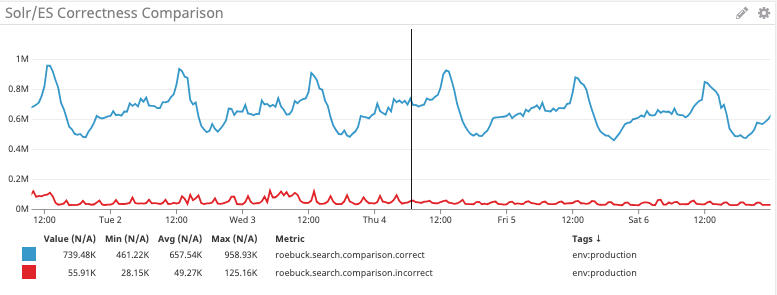
This graph shows the number of search results that match exactly the number of results between the two systems in blue, and those that differ in number in red.
As part of our roll-out, all default searches, those searches on the empty string, have already been provided by Elasticsearch for several months now -- so users are already seeing and using Elasticsearch results without problems.
There are limitations to what we can learn from this kind of comparison, however. At best we can only infer the intent of a particular search, and catalog data is fluid.
Known Differences
The differences below are largely fundamental, or the result of decisions reached after extensive analysis of search results -- they are impossible to completely eliminate.
Stemming
Stemming is the process of reducing inflected (or sometimes derived) words to their word stem, base or root form — generally a written word form.
A stemmer for English operating on the stem cat should identify such strings as cats, catlike and catty. A stemming algorithm might also reduce the words fishing, fished and fisher to the stem fish. The stem need not be a word, for example the Porter algorithm reduces argue, argued, argues, arguing and argus to the stem argu.
Our existing search uses the Lancaster (Paice/Husk) stemmer, this algorithm is generally regarded as being overly aggressive — this results in a lack of distinction, for example lighter and light would be regarded as the same term under Lancaster.
Elasticsearch uses a more recent and much less aggressive algorithm (Porter2) that has gained broad adoption in industry and is generally regarded as a significant improvement (Lancaster is now rare). The change of stemmer potentially impacts a significant (~35%) proportion of searches: that is not to say that results will be different, just that they might be different — but in general this should be for the better: that said, some subset of customers may be reliant on the old behavior.
Relevance
Our existing search seems to have a more strict TF normalization. This causes a different relevance sort for terms that are found in larger fields (i.e. existing considers the match less relevant since it gives less weight to the term as it is smaller relative to the length of the document).
Special Characters
Special characters are stripped inside our existing search, this pretty much equates to stripping punctuation and related characters — instead of stripping, we generally escape them in Elasticsearch, thus there is a chance that a search will instead take them into account.
Term Handling
Existing search queries perform `term smooshing` whereas in Elasticsearch we drop malformed terms, consider this search with an empty tags: term: q=tags: state:ACTIVE
- Existing:
tags:state:ACTIVE— search for videos with a tag ofstate:ACTIVE - Elasticsearch:
state:ACTIVE— drop the empty term
There are a number of subtle edge cases related to handling dangling punctuation and queries that are generally malformed, we attempt to produce what we think the query was intended to be, but in these cases we’re unfortunately guessing what a user might have intended (when really we should have returned an error allowing them to refine their search)
Playable Only
There are two mechanisms for restricting a search to videos that are currently playable: the query can include a flag, or the query itself can require some aspect of playability.
- Existing: this is queried based on the value of a field that is updated
- Elasticsearch: this is queried based on computed date ranges
Elasticsearch should generally be more accurate and produce better results (there is a lag associated with the existing mechanism, and the flag maintenance mechanism is not entirely reliable).
Index Accuracy
The Elasticsearch index is ‘fresher’ than the existing index and tends to reflect updates faster — this is not always the case, but in general the experience with Elasticsearch is that results will more accurately reflect the state of the underlying catalog data. Both existing and Elasticsearch are distributed systems and thus not entirely consistent in the results they return: a repeated query against either system can potentially return different results (especially in the case where there are a number of concurrently running delete operations).
Existing search results change based on the state of the shard an account is allocated to — the global state of a particular shard can (and does) impact the results of any particular query: Elasticsearch does not have this deficiency.
Examples
Example 1
Let’s say there are two videos with the following titles:
Video#1: has the title “Don’t look into the light”
Video#2: has the title “Using a lighter to make a campfire”
The user wishes to return all videos that must have the word “light”. Using the CMS API, the query would look like:
q=%2Blight or q=+light
With the existing search, this will return both of the videos in the order:
Video#2 - “Using a lighter to make a campfire”
Video#1 - “Don’t look into the light”
There are two problems with this:
- Relevance: The order is incorrect. “Don’t look into the light” (Video#2) should appear before “Using a lighter to make a campfire” (Video#1)
- Accuracy: “Using a lighter to make a campfire” shouldn’t even appear in the result set as the word “light” doesn’t appear in the video title at all.
With Elasticsearch, this will return only video one:
Video#1 - “Don’t look into the light”
This is an improvement because:
- Relevance: The order is correct.
- Accuracy: Only Video one is returned as it’s the only video with the word “light” in the title.
Example 2
As described in our CMS API documentation for stemming, stemming is supported, but not partial word searches. So let’s say there are 5 videos with the following titles:
Video#1 - "Parking Ban Announced"
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
Video#4 - "Bank Holiday"
Video#5 - "Bandit Captured"
The user wishes to return all videos that must have the word ban in the name field. Using the CMS API, the query would look like:
q=%2Bname%3Aban or q=+name:ban
The expectation is that “Ban”, “Banning” and “Banned” would produce search results as “Ban” is a stem of all three.
However, with the current search system, this will return all five videos in this order:
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
Video#1 - "Parking Ban Announced"
Video#4 - "Bank Holiday"
Video#5 - "Bandit Captured"
Again, there are two problems with this:
- Relevance: The order is incorrect. "Parking Ban Announced" should be the first video returned as it has the word “Ban” in it.
- Accuracy: "Bank Holiday" and "Bandit Captured" should not be returned at all as “Ban” is not part of the word “Bank” or “Bandit”.
With Elasticsearch, the results look like:
Video#1 - "Parking Ban Announced"
Video#2 - "Parking to be Banned"
Video#3 - "City Banning Parking"
This is an improvement because:
- Relevance: The order is correct.
- Accuracy: Only Videos with the stems of the word “Ban” (“Ban”, “Banning” and “Banned”) are returned.